
ADMM-NN: An Algorithm-Hardware Co-Design Framework of DNNs Using Alternating Direction Method of Multipliers
Published in ASPLOS 2018, 2018
Recommended citation: Ao Ren*, Tianyun Zhang*, Shaokai Ye, Jiayu Li, Wenyao Xu, Xuehai Qian, Xue Lin, Yanzhi Wang Architecture Support for Programming Langueages and Operating Systems 2019 ASPLOS2019
Abstract
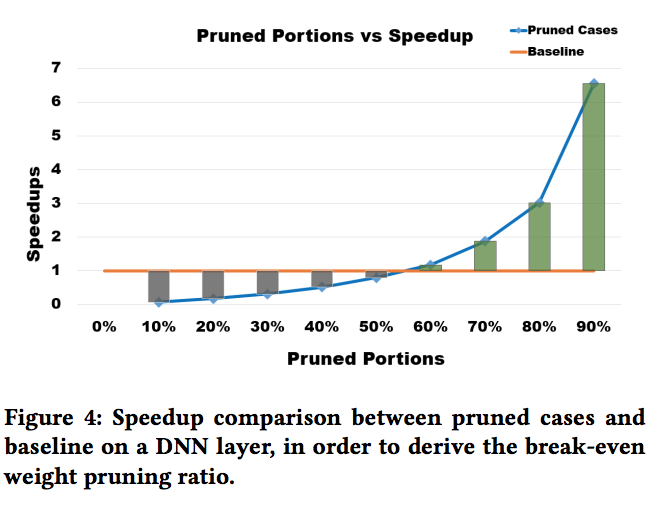
To facilitate efficient embedded and hardware implementations of deep neural networks (DNNs), two important categories of DNN model compression techniques: weight pruning and weight quantization are investigated. The former leverages the redundancy in the number of weights, whereas the latter leverages the redundancy in bit representation of weights. However, there lacks a systematic framework of joint weight pruning and quantization of DNNs, thereby limiting the available model compression ratio. Moreover, the computation reduction, energy efficiency improvement, and hardware performance overhead need to be accounted for besides simply model size reduction. To address these limitations, we present ADMM-NN, the first algorithm-hardware co-optimization framework of DNNs using Alternating Direction Method of Multipliers (ADMM), a powerful technique to deal with non-convex optimization problems with possibly combinatorial constraints. The first part of ADMM-NN is a systematic, joint framework of DNN weight pruning and quantization using ADMM. It can be understood as a smart regularization technique with regularization target dynamically updated in each ADMM iteration, thereby resulting in higher performance in model compression than prior work. The second part is hardware-aware DNN optimizations to facilitate hardware-level implementations.